|
Prakamya Mishra I'm an applied research engineer at AMD AI in Seattle, where I am part of the GenAI team led by Zicheng Liu, working on novel techniques to efficiently train LLMs & image/video generation AI models on large-scale clusters. Previously, I was a graduate researcher in BioNLP Lab at UMass Amherst (Mentors: Hong Yu & Zonghai Yao), graduate research with Amazon Science NLU Team (Mentor: Mayank Kulkarni), and an applied scientist intern at Amazon Science SLU Team (Mentors: Abhishek Malali & Masha Belyi). I did my Masters in Computer Science from UMass Amherst. |

|
ResearchI'm interested in natural language processing, deep learning, and generative AI. Most of my research is about language models, representation learning and applications of NLP. |
.png)
|
SAND-Math: Using LLMs to Generate Novel, Difficult and Useful Mathematics Questions and Answers
Chaitanya Manem* Pratik Prabhanjan Brahma, Prakamya Mishra, Zicheng Liu, Emad Barsoum NeurIPS 2025, MATH-AI Workshop Paper / Dataset / Introducing SAND-Math, a novel pipeline effectively generating novel and complex math problems by leveraging the latent abilities of SOTA models. |

|
Introducing Instella-Math: A Fully Open Language Model with Reasoning Capability
Xiaodong Yu Jiang Liu, Yusheng Su, Gowtham Ramesh, Zicheng Liu, Prakamya Mishra, Sudhanshu Ranjan, Jialian Wu, Ximeng Sun, Ze Wang, Emad Barsoum AMD, GenAI Blog / Model Card / Code Introducing Instella-Math, the first reasoning-focused language model trained with long chain-of-thought reinforcement learning entirely on AMD GPUs. |
.png)
|
TTT-Bench: A Benchmark for Evaluating Reasoning Ability with Simple and Novel Tic-Tac-Toe-style Games
Prakamya Mishra*, Jiang Liu, Jialian Wu, Xiaodong Yu Zicheng Liu, Emad Barsoum EMNLP 2025, Main Paper / Website / Dataset Introducing TTT-Bench, a new benchmark that is designed to evaluate basic reasoning abilities in LRMs through a suite of four two-player Tic-Tac-Toe-style games. |

|
Introducing Instella-Long: A Fully Open Language Model with Long-Context Capability
Jialian Wu*, Jiang Liu*, Sudhanshu Ranjan*, Xiaodong Yu* Gowtham Ramesh, Prakamya Mishra*, Zicheng Liu*, Yusheng Su, Ximeng Sun, Ze Wang, Emad Barsoum AMD, GenAI Blog / Model Card / Code Announcing Instella-Long, a long-context language model continually trained from Instella-3B-Instruct on AMD Instinct™ MI300X GPUs. |
|
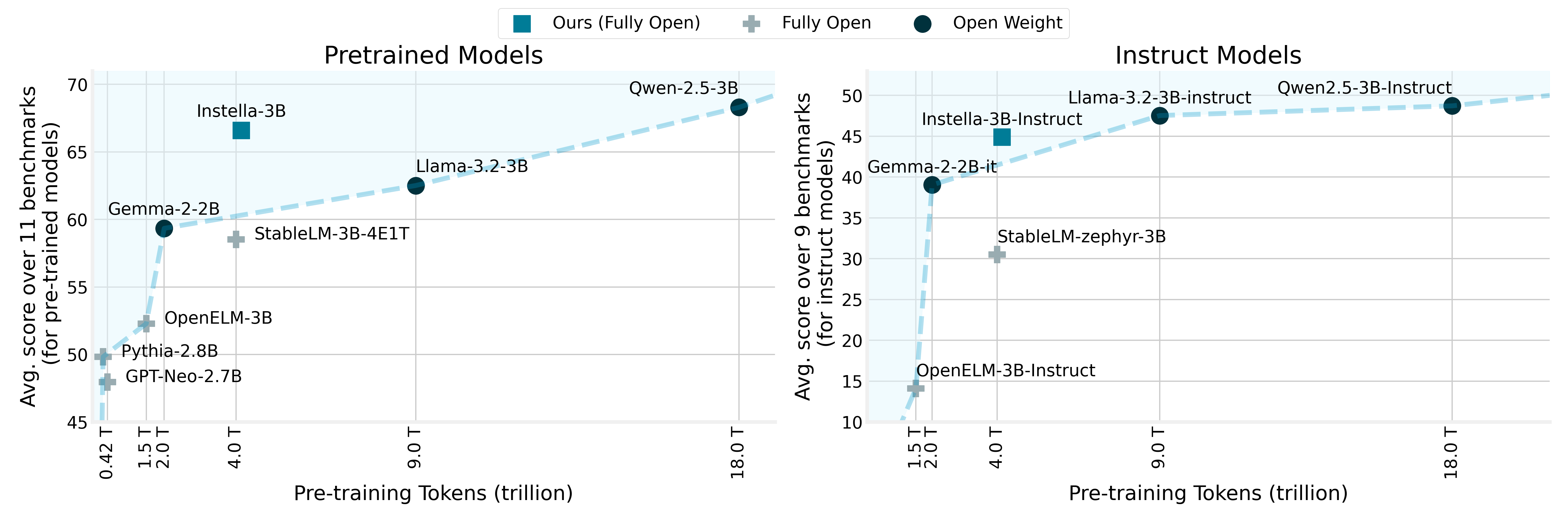
Introducing Instella: New State-of-the-art Fully Open 3B Language Models
Jiang Liu*, Jialian Wu*, Xiaodong Yu* Prakamya Mishra*, Sudhanshu Ranjan*, Zicheng Liu* Chaitanya Manem, Yusheng Su, Pratik Prabhanjan Brahma, Gowtham Ramesh, Ximeng Sun, Ze Wang, Emad Barsoum AMD, GenAI Blog / Model Card / Code Announcing Instella, a series of 3 billion parameter language models developed by AMD, trained from scratch on 128 Instinct MI300X GPUs. |

|
Introducing the First AMD 1B Language Models: AMD OLMo
Jiang Liu*, Jialian Wu*, Prakamya Mishra*, Zicheng Liu* Sudhanshu Ranjan, Pratik Prabhanjan Brahma, Yusheng Su, Gowtham Ramesh, Peng Sun, Zhe Li, Dong Li, Lu Tian, Emad Barsoum AMD, GenAI Blog / Model Card AMD OLMo are a series of 1 billion parameter language models pre-trained with 1.3 trillion tokens on 16 nodes, each with four (4) AMD Instinct™ MI250 GPUs. |
|
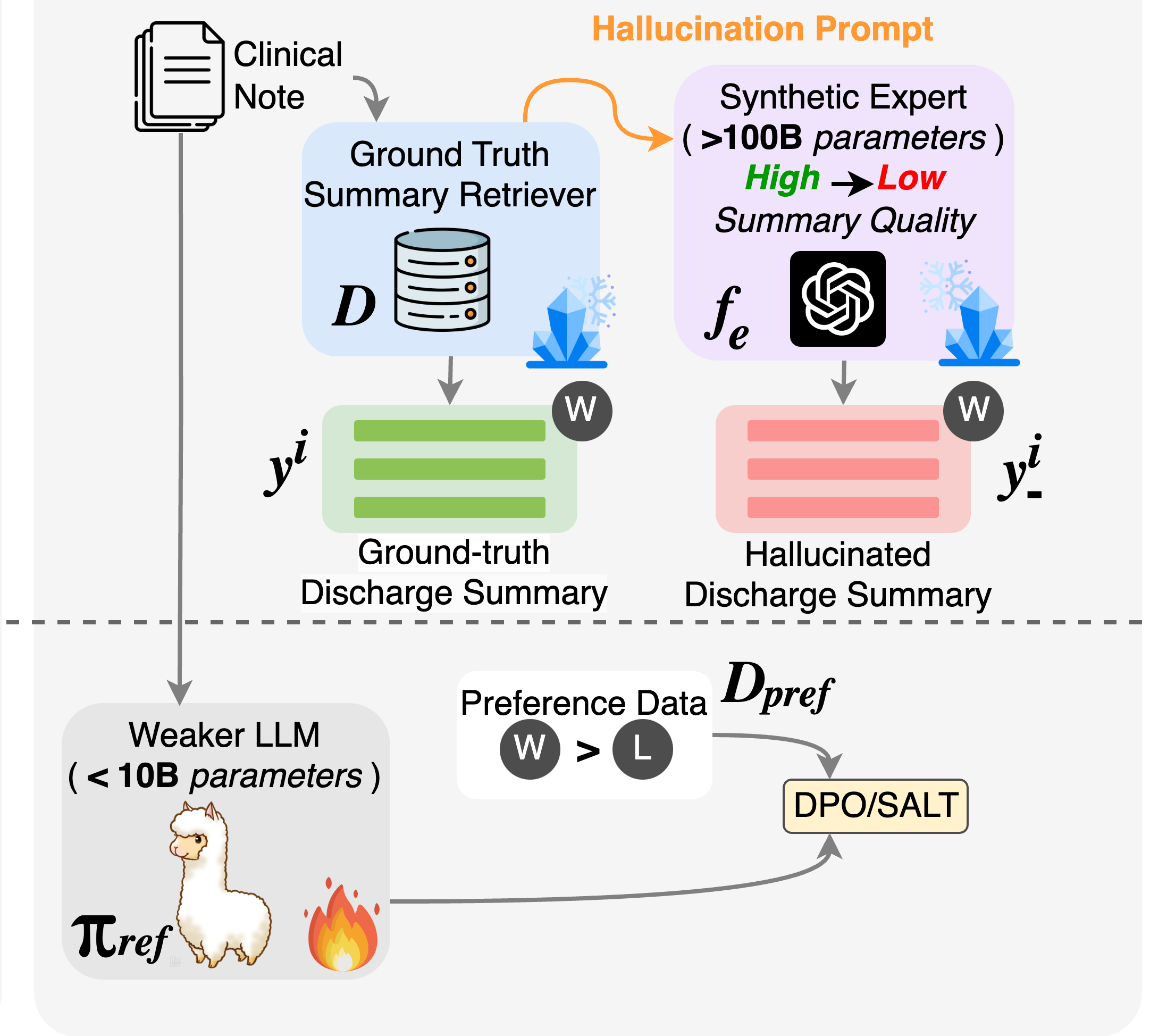
SYNFAC-EDIT: Synthetic Imitation Edit Feedback for Factual Alignment in Clinical Summarization
Prakamya Mishra*, Zonghai Yao*, Parth Vashisht, Feiyun Ouyang, Beining Wang, Vidhi Dhaval Mody, Hong Yu EMNLP 2024, Main arXiv This study leverages synthetic edit feedback to improve factual accuracy in clinical summarization using DPO and SALT techniques. Our approach demonstrates the effectiveness of GPT-generated edits in enhancing the reliability of clinical NLP applications. |
|
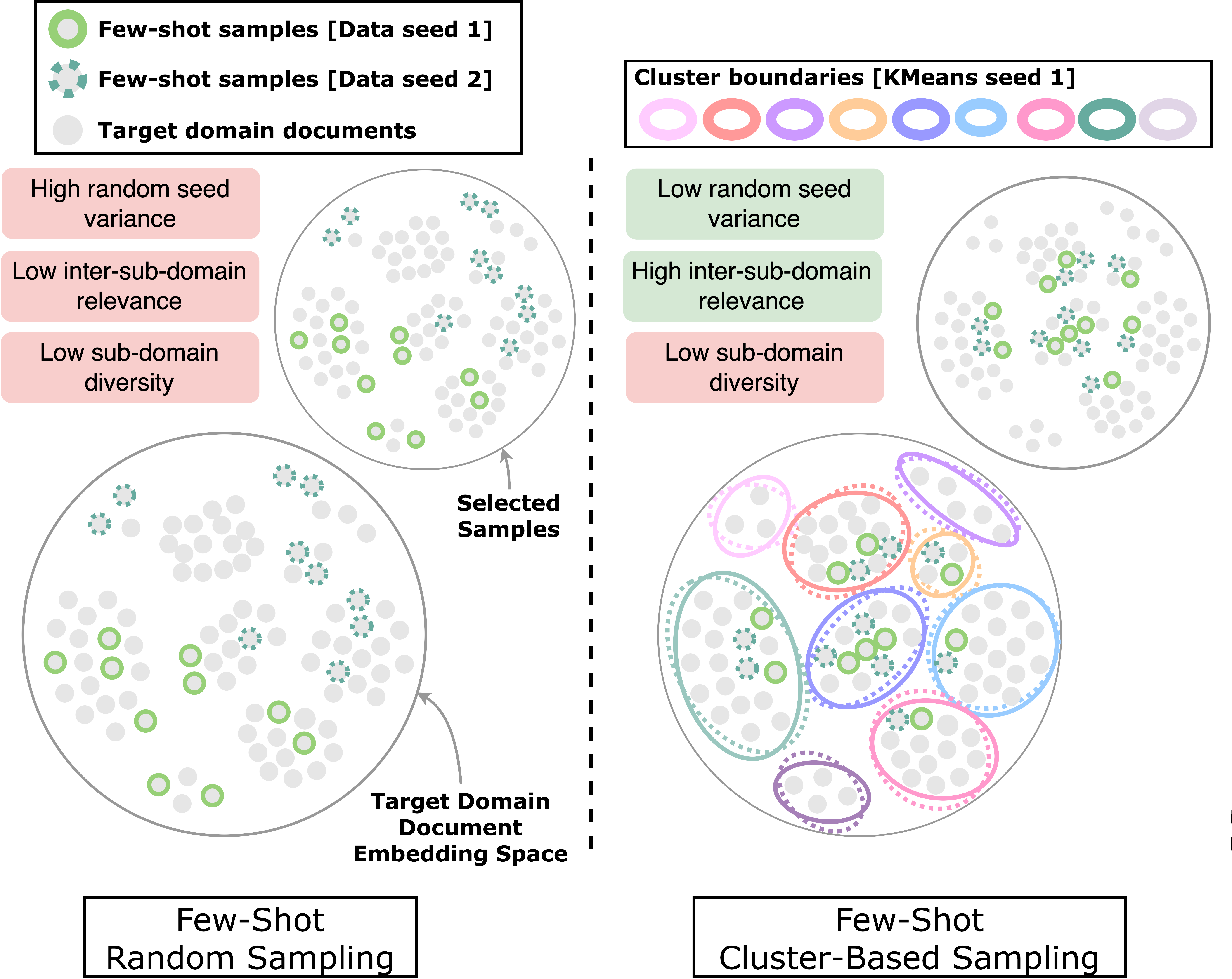
Clustering-based sampling for few-shot cross-domain keyphrase extraction
Prakamya Mishra*, Lincy Pattanaik*, Arunima Sundar*, Nishant Yadav, Mayank Kulkarni EACL 2024, Findings Paper / Presentation We propose a novel clustering-based few-shot sampling approach that leverages intrinsically available sub-domain information as topics from the dataset to extract few-shot samples to be labeled from the target domains and be used for fine-tuning. |
|
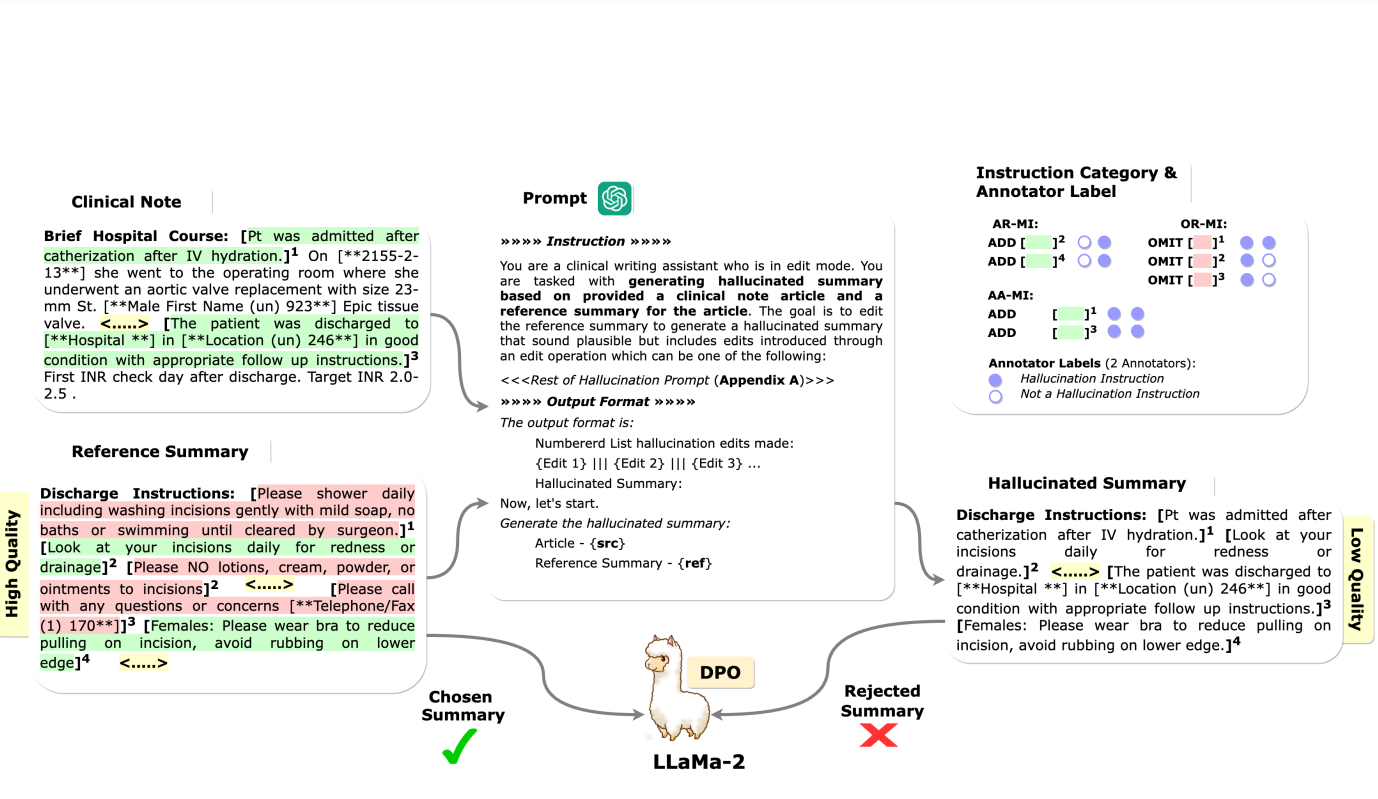
Synthetic Imitation Edit Feedback for Factual Alignment in Clinical Summarization
Prakamya Mishra*, Zonghai Yao*, Shuwei Chen, Beining Wang, Rohan Mittal, Hong Yu NeurIPS 2023, SyntheticData4ML workshop Paper In this work, we propose a new pipeline using ChatGPT instead of human experts to generate high-quality feedback data for improving factual consistency in the clinical note summarization task. |

|
STEPs-RL: Speech-Text Entanglement for Phonetically Sound Representation Learning
Prakamya Mishra PAKDD 2021, Long paper (Oral Presentation) Paper In this work, we present a novel multi-modal deep neural network architecture that uses speech and text entanglement for learning phonetically sound spoken-word representations. |
|
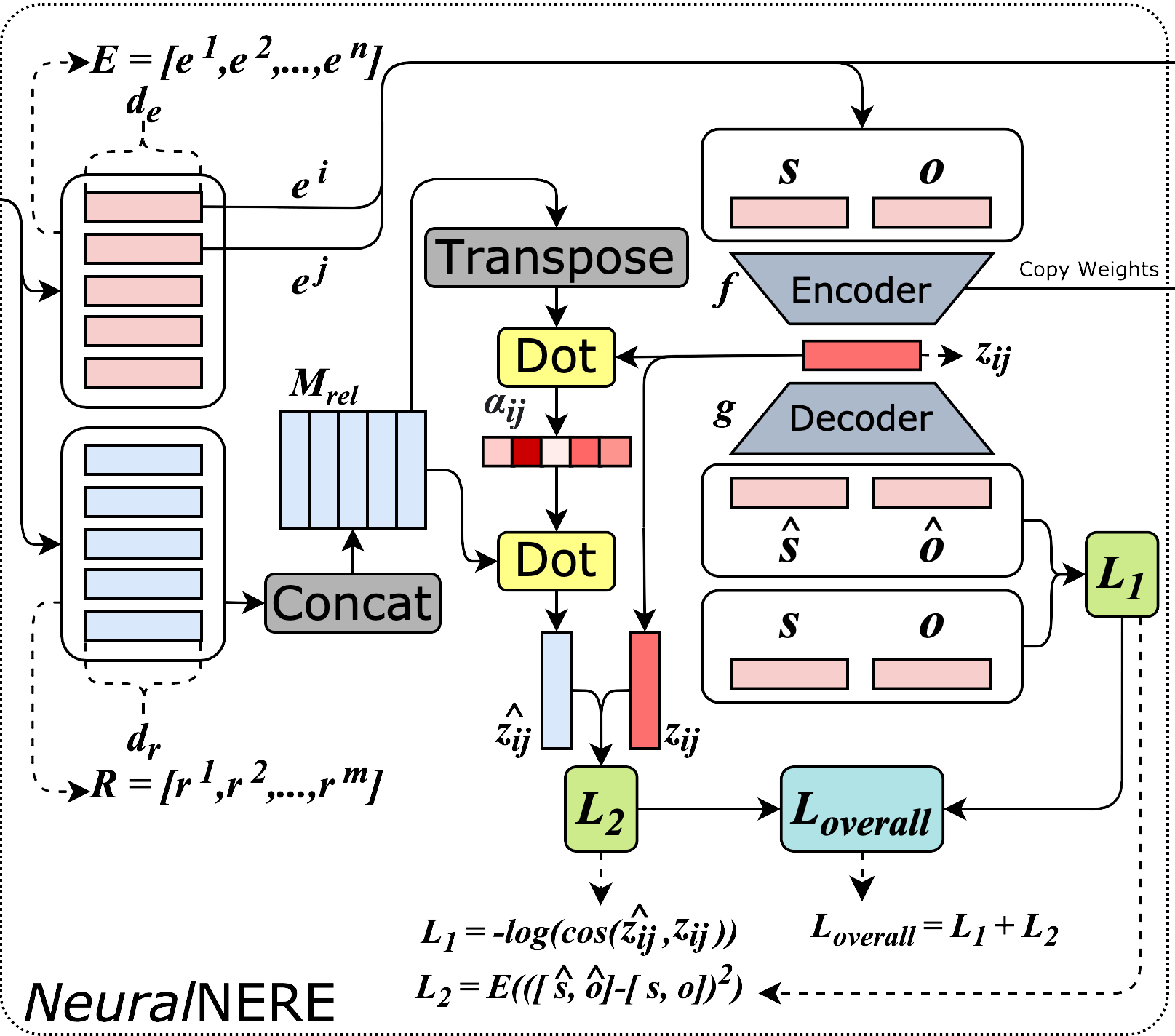
NeuralNERE: Neural Named Entity Relationship Extraction for End-to-End Climate Change Knowledge Graph Construction
Prakamya Mishra, Rohan Mittal ICML 2021, Tackling Climage Change using Machine Learning workshop (Spotligh Presentation) Paper / Presentation We propose NeuralNERE, an end-to-end Neural Named Entity Relationship Extraction model for constructing climate change knowledge graphs directly from the raw text of relevant news articles. Additionally, we introduce a new climate change news dataset (called SciDCC dataset) containing over 11k news articles scraped from the Science Daily website. |

|
Bi-ISCA: Bidirectional Inter-Sentence Contextual Attention Mechanism for Detecting Sarcasm in User Generated Noisy Short Text
Prakamya Mishra, Saroj Kaushik, Kuntal Dey IJCAI 2021, MRC-HCCS wrokshop Paper Developed novel Bi-directional Inter-Sentence Contextual Attention mechanism (Bi-ISCA) to capture inter-sentence dependencies for detecting sarcasm. Explained model behaviors and predictions by analyzing the attention maps and identifying words responsible for invoking sarcasm. |
Miscellanea |
| Reviewer at EMNLP'23, EACL SRW'24, EMNLP'24, NAACL'24, NeurIPS'24, ICLR'25, AISTAT'25 |
|
Design and source code from Jon Barron's website. |